Keepsake Version control for machine learning
Keepsake versions machine learning experiments and models.
In your training script, you use a Python library to upload files (like code and model weights) and metadata (like hyperparameters and metrics) to Amazon S3 or Google Cloud Storage.
You can get the files and metadata back out using the command-line interface or from within a notebook using the Python library.
Recording experiments
Experiments are recorded directly in your training script or notebook using the Python library:
import torchimport keepsakedef train():experiment = keepsake.init(path=".", params={...})model = Model()for epoch in range(params["num_epochs"]):# ...torch.save(model, "model.torch")experiment.checkpoint(path="model.pth", metrics={...})
These two lines will record:
- The code used to run the training script
- The hyperparameters
- Training data version, depending on how your training data is stored
- Python package versions
- The model weights on each iteration
- Metrics on each iteration
All this information is put in a repository, which is defined in the file keepsake.yaml. For example:
repository: "s3://keepsake-hooli-hotdog-detector"
A repository can be stored on Amazon S3, Google Cloud Storage, or the local disk. The format of the repository is explained below.
Getting information out
The versioned information can be accessed with the command-line interface:
$ keepsake lsEXPERIMENT STARTED STATUS USER LEARNING_RATE LATEST CHECKPOINTc9f380d 16 seconds ago stopped ben 0.01 d4fb0d3 (step 99)a7cd781 9 seconds ago stopped ben 0.2 1f0865c (step 99)$ keepsake checkout d4fb0d3═══╡ Copying the code and weights from d4fb0d3 into the current directory...
You can also use the Python library to access this information:
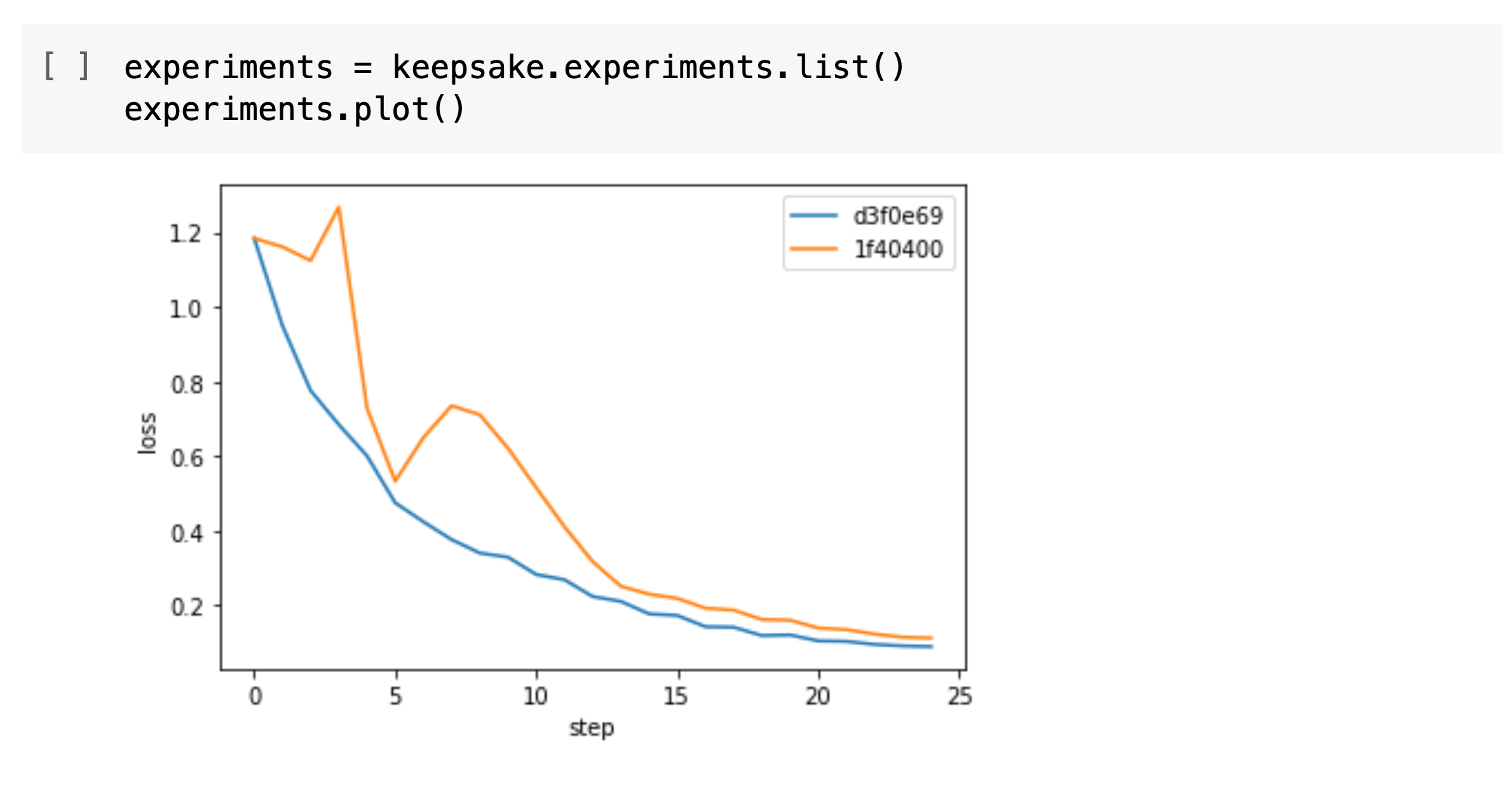
The Python library can also load saved models to run inferences:

Experiments
The core concept in Keepsake is the experiment. It represents a run of your training script, and tracks the inputs to the training process so you can figure out how a model was trained.
It records:
- Your code, or any other files or directories.
- Any key/value data, such as hyperparameters and pointers to your training data.
- The version of any Python packages imported.
- The user who started the training script.
- The host where the training script is running.
Checkpoints
Within experiments are checkpoints. They each represent a version of the outputs of the training process. Conceptually, you can think of them like commits in a version control system: each one is a particular version of your machine learning model.
It records:
- Your model weights, or any other files or directories.
- Metrics, to record the performance of your model at that point.
Repositories
A repository is where your experiments and checkpoints are stored. You typically have one repository per model, so you can group experiments based on the model you're working on.
It is tied to the directory that your model is in, similar to the idea of a repository in a version control system. You define what repository a directory uses by defining it in keepsake.yaml:
repository: "s3://keepsake-hooli-hotdog-detector"
Repositories can be stored on Amazon S3, Google Cloud Storage, or the local disk. Learn more about keepsake.yaml in the reference.
Repositories are just plain files – there is nothing magical going on. This is the directory structure:
repository.json– A file that marks this directory as a Keepsake repository, and records the version of the data format within it.checkpoints/<checkpoint ID>.tar.gz– A tarball of the files saved when you create a checkpoint.experiments/<experiment ID>.tar.gz– A tarball of the files in your project's directory when an experiment was created.metadata/experiments/<experiment ID>.json– A JSON file containing all the metadata about an experiment and its checkpoints.metadata/heartbeats/<experiment ID>.json– A timestamp that is written periodically by a running experiment to mark it as running. When the experiment stops writing this file and the timestamp times out, the experiment is considered stopped.
Further reading
Next, you might want to take a look at:
- The CLI tutorial or the notebook tutorial to learn how to use Keepsake by building a simple model.
- The Python library reference.
- How to store data in the cloud
- How to version training data